【译】使用 Webpack 拆包的 100% 正确的做法 / The 100% correct way to split your chunks with Webpack

技术积累,从翻译优质文章开始。本文翻译自:The 100% correct way to split your chunks with Webpack
为自己网站的用户找出推送文件的最好方式是一件很麻烦的事。 太多不同的场景,不同的技术,不同的术语了。
在这篇 Blog 中,我希望告诉你你想知道的一切,你可以:
-
了解哪种文件拆分策略最适合你的网站和用户
-
知道怎么去做
根据 Webpack 词汇表,有两种不同类型的文件拆分方式。 这两个概念听起来可以互换,但显然并不是这样:
Bundle splitting:创建更多,更小的文件(但不管怎样,每个网络请求中都要加载它们),来优化缓存。
Code splitting:动态加载代码,用户可以仅下载他们正在查看的网站部分所需的代码。
第二个概念听起来更加吸引人啊,对吧?其实,许多关于此的文章都似乎认为这是加载 JS 文件的唯一有价值的 case。
但是我来告诉你,对于多数站点来说,第一个才是更有价值的方式,而且应该是你对网站所做的首要的事情。
我们接着深入往下看。
Bundle splitting
Bundle splitting 背后的想法非常简单。 如果你有一个巨大的文件,当你更改了一行代码,用户必须再次下载整个文件。 但是,如果我们将其拆分为两个文件,则用户只需下载已更改的文件,浏览器会从缓存中读取另一个文件。
值得注意的是,由于 Bundle splitting 是完全针对缓存的,所以对于首次访问的用户而言(拆与不拆)没什么区别。
(我认为太多的性能讨论都与首次访问网站有关。也许这部分是因为「第一印象很重要」,另一块是因为它很容易量化。)
当涉及到频繁访问的用户时,量化性能优化带来的影响可能很麻烦,但我们必须量化!
下面是我在前一段中提到的情况:
-
Alice 每周访问我们的网站一次,持续10周
-
我们每周一次发版
-
我们每周都会更新「产品列表」页
-
我们还有一个「产品详情」页,现在我们先不管它
-
在第5周,我们向网站添加一个新的 npm 包
-
第8周,我们更新了其中一个既有的 npm 包
一些人(比如我)希望这种情况尽可能符合实际。 这种做法并不好。实际情况并不重要,我们之后会找出原因。 (先留个铺垫!)
比较基准值
假设我们的 JavaScript 包总大小为 400 KB,目前以单个文件main.js的形式加载。
我们的 Webpack config 看起来像这样(省略了无关的配置内容):
const path = require('path');
module.exports = {
entry: path.resolve(__dirname, 'src/index.js'),
output: {
path: path.resolve(__dirname, 'dist'),
filename: '[name].[contenthash].js',
},
};
(对于那些刚开始学习缓存更新策略的人:每当我提到main.js时,实际上是在说main.xMePWxHo.js之类的东西,这一坨疯狂的字母串是文件内容的哈希。这意味着当程序中代码更改时会产生不同的文件名 ,从而迫使浏览器下载新文件。)
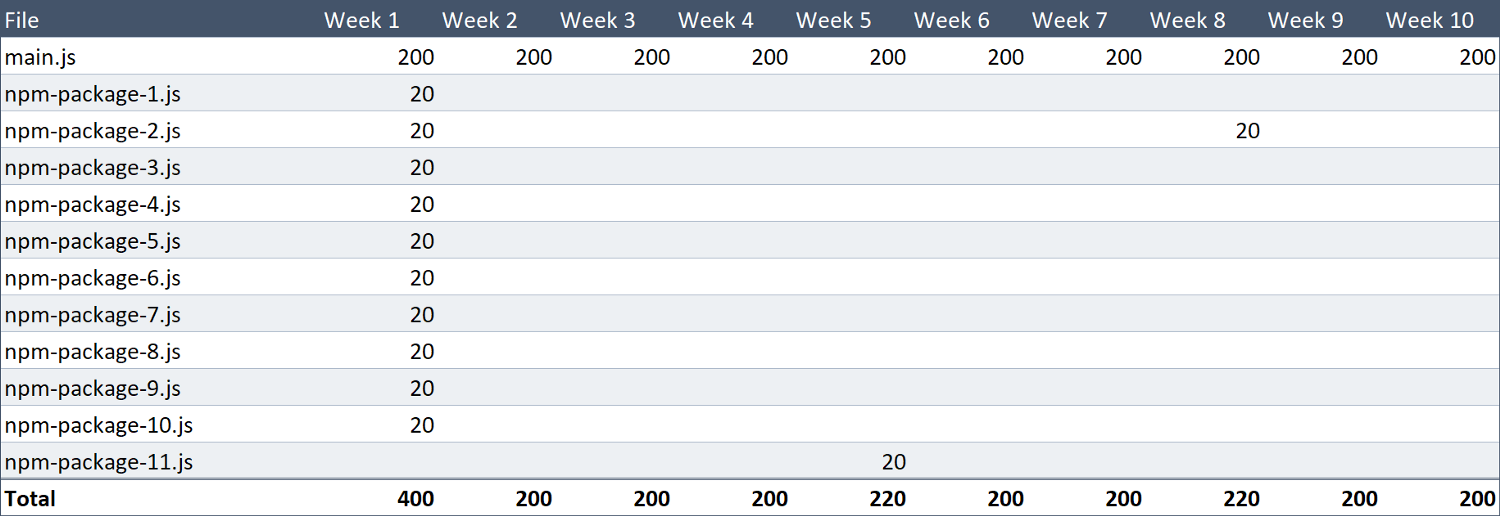
每周我们会对网站进行一些新更改,包中内容哈希都会更改。 所以,在每周 Alice 访问我们的网站时,都必须要下载一个新的400 KB文件。
如果我们要做一个花里胡哨的表,它看起来就像这样。

这10周积起来,就是 4.12 MB。
我们可以做得更好。
拆分出 vendor 包
让我们把包拆成main.js和vendor.js。
很简单,类似于:
const path = require('path');
module.exports = {
entry: path.resolve(__dirname, 'src/index.js'),
output: {
path: path.resolve(__dirname, 'dist'),
filename: '[name].[contenthash].js',
},
optimization: {
splitChunks: {
chunks: 'all',
},
},
};
Webpack 4 尽力为你做到了最好,你不必告诉它你怎么拆分你的 bundle。
这会导致一些话术比如:「哦🐂🍺,Webpack整挺好!」
还有许多类似于「你tm到底对我的 bundle 做了什么?!」的疑问。
铛铛!加上optimization.splitChunks.chunks = 'all'是一种「把所有 node_modules里的东西栋放到一个叫vendors~main.js的文件」的说法。
有了这个基本的 bundle splitting 之后,Alice 还会在每次访问时下载一个新的200 KB的 main.js,但只会在第一周,第八周和第五周下载这个 200 KB 的 vendor.js。

总共 2.64 MB。
减少36%,配置中添加了五行代码,还不赖。 在继续读这篇文章之前,现在就去实践下。 如果需要从Webpack 3 升级到4,不要担心,它非常无痛(而且免费!)。
我觉得这种性能提升可能会更抽象,因为分散在十个星期,但其实交付给忠实用户的字节数减少了36%,我们应该为自己感到自豪。
但我们还可以做得更好。
把每个 npm 包都拆出来
我们的vendor.js遇到了与原来main.js文件相同的问题——对其中一部分进行更改意味着需要重新下载它的全部。
所以为什么不为每个npm包单独准备一个文件呢? 这很容易做到。
那让我们将react,lodash,redux,moment等分成不同的文件:
const path = require('path');
const webpack = require('webpack');
module.exports = {
entry: path.resolve(__dirname, 'src/index.js'),
plugins: [
new webpack.HashedModuleIdsPlugin(), // 确保 hash 不被意外改变
],
output: {
path: path.resolve(__dirname, 'dist'),
filename: '[name].[contenthash].js',
},
optimization: {
runtimeChunk: 'single',
splitChunks: {
chunks: 'all',
maxInitialRequests: Infinity,
minSize: 0,
cacheGroups: {
vendor: {
test: /[\\/]node_modules[\\/]/,
name(module) {
//取得名称。例如 /node_modules/packageName/not/this/part.js
// 或 /node_modules/packageName
const packageName = module.context.match(/[\\/]node_modules[\\/](.*?)([\\/]|$)/)[1];
// npm package 是 URL 安全的,但有些服务不喜欢 @ 符号
return `npm.${packageName.replace('@', '')}`;
},
},
},
},
},
};
这篇文档 会很好地说明这里的大多数内容,但是我要向你解释一些有趣的部分,因为它们花了我巨长的时间才弄对。
-
Webpack 拥有一些聪明但实际上有点傻的默认配置,像:分割输出文件时最多可以包含3个文件,最小文件大小为30 KB(即比这小的文件都可以合并在一起)。 所以我覆盖了这些配置。
-
cacheGroups是我们定义 Webpack 如何将 chunks 到输出到 bundle 的规则。 这里有一个叫做「vendor」的,任何node_modules的包都在这里。 通常,你只需将输出文件的名称定义为字符串。 但是我将name定义为一个函数(将为每个已解析的文件调用该函数),从模块路径返回包的名称。 结果是,每个包都会生成一个文件,比如npm.react-dom.899sadfhj4.js。 -
发包时包名称必须是 URL安全的。所以我们不必用
encodeURI处理packageName。但是,我发现 .NET服务无法提供名称中带有@的文件(来自范围限定的包),所以我在此代码段中替换了该命名。 -
整个配置很棒,因为它是一劳永逸的。 它无需维护——我不需要按名称引用任何包。
这时,Alice 仍每周重新加载我们200 KB的main.js文件;在首次访问时仍将下载200 KB的 npm 包,但她永远不会再次下载相同的包。
这是2.24MB。
与比较基准值相比减少了44%,仅仅从博客文章中 copy/plate 了某些代码的你来说,这非常酷。
我在想会不会有可能超过50%?
那不是盖了帽了吗。
拆分应用的代码区域
让我们关注下可怜的 Alice 一次又一次(甚至再一次)下载的main.js文件。
前面我提到过,我们在此站点上有两个截然不同的部分:一个产品列表和一个产品详情页。 这些区域中每个区域的自身的代码为 25 KB(保留150 KB的共享代码)。
现在,我们的“产品详情”页面变化不大,因为我们做得如此完美。 因此,如果我们将其分成单独的文件,则大多数时候都可以从缓存中提供。
对此,我们应该搞些事情。
我们手动地添加一些入口点,告诉 Webpack 为其中的每项创建一个文件。
module.exports = {
entry: {
main: path.resolve(__dirname, 'src/index.js'),
ProductList: path.resolve(__dirname, 'src/ProductList/ProductList.js'),
ProductPage: path.resolve(__dirname, 'src/ProductPage/ProductPage.js'),
Icon: path.resolve(__dirname, 'src/Icon/Icon.js'),
},
output: {
path: path.resolve(__dirname, 'dist'),
filename: '[name].[contenthash:8].js',
},
plugins: [
new webpack.HashedModuleIdsPlugin(), // 确保 hash 不被意外改变
],
optimization: {
runtimeChunk: 'single',
splitChunks: {
chunks: 'all',
maxInitialRequests: Infinity,
minSize: 0,
cacheGroups: {
vendor: {
test: /[\\/]node_modules[\\/]/,
name(module) {
//取得名称。例如 /node_modules/packageName/not/this/part.js
// 或 /node_modules/packageName
const packageName = module.context.match(/[\\/]node_modules[\\/](.*?)([\\/]|$)/)[1];
// npm package 是 URL 安全的,但有些服务不喜欢 @ 符号
return `npm.${packageName.replace('@', '')}`;
},
},
},
},
},
};
靠谱的 Webpack还会为在 ProductList 和 ProductPage 之间共享的内容创建文件,使得我们不会得到重复的代码。
大多数情况下,这将为亲爱的 Alice 省下额外的50 KB下载量。
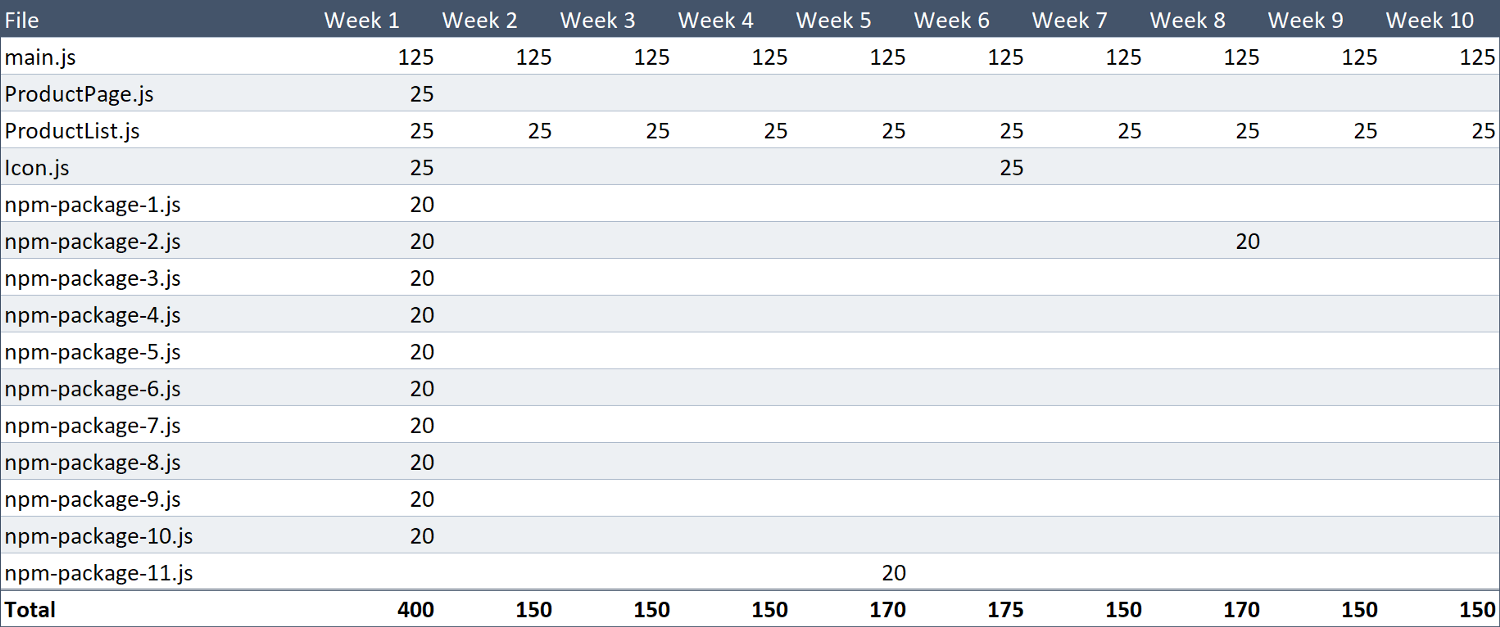
这些仅仅1.815 MB!
我们已经为 Alice 节省了高达56%的下载量,并且这种节省将(在我们的理论场景中)一直持续到时间尽头。
我之前提到过,在测试之下的实际情况并不重要。 这是因为,无论你遇到什么情况,结论都是相同的:将你的应用拆分为合理的小文件,你的的用户就会下载更少的代码。
很快,我将要讨论「code splitting」——另一种类型的文件拆解——但首先,我想解决你现在在想的三个疑惑点。
#1:有很多网络请求会不会很慢?
答案是很大声的“不”。
在 HTTP/1.1 时代曾经是这种情况,但是在 HTTP/2 中却不是这种情况。
尽管,这篇2016年的文章和Khan Academy 2015年的帖子都得出了这样的结论:即使使用HTTP/2,下载太多文件的速度仍然较慢。 但在这两个帖子中,「太多」文件意味着「几百」。 因此,请记住,如果你有数百个文件,才可能会达到并发限制。
或者你想知道追溯到 Windows 10上的 IE11 对 HTTP/2 的支持。我对使用比这更早版本的环境的人进行了详尽的调查,他们一致向我保证,他们不在乎网站加载的速度如何。
#2:会不会 每个Webpack bundle 中都有开销/样板代码?
确实。
#3:会不会因为拥有多个小文件而丧失了压缩方面(的优势)?
对,也确实会。
呃,糟了:
-
更多的文件 = 更多 Webpack 样板代码
-
更多的文件 = 更少的压缩
让我们对它来一个量化,使得我们确切知道需要担心的程度。
……
OK,我刚做了一个测试,一个190 KB的站点分为19个文件,添加到发送给浏览器的总字节数中大约增加了2%。
所以……对于第一次访问有2%的增量,与此同时在之后的访问有 60% 减少量,直到宇宙的尽头。
因此我们所需要担心的程度正确的是:完全没有。
在测试 1 vs 19 个文件时,我在想我可以在一些不同的网络上使用它,包括HTTP/1.1。
然后下面是我搞的表格,强力支撑了“文件越多越好”的想法:
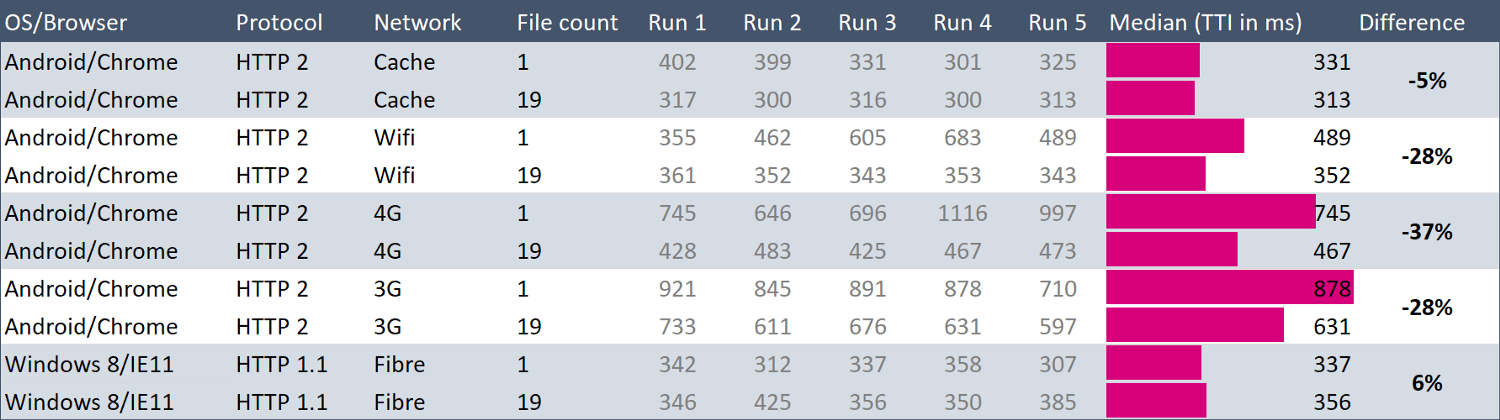
在 3G 和 4G 上,当有 19 个文件时,此站点的加载时间减少了 30%。
真的如此吗?
这是噪点非常多的数据。 例如,在 Run 2 的 4G 网络上,站点加载了646毫秒,然后两次运行则花费了 1116毫秒——在什么都没做的情况下长了73%。 因此,宣称 HTTP/2 的速度提高了30%似乎有点狡猾。
(即将推出:一种自定义图表类型,旨在可视化页面加载时间的差异。)
我建了这张表,尝试量化 HTTP/2 的区别,但事实上我能唯一能说的是“可能没有多大区别”。
真正奇怪是最后两排。 那是旧的 Windows 和 HTTP/1.1,我打赌速度会慢很多,但并非如此。我想我需更慢的网络。
讲故事的时间到了! 我从微软官网下载了Windows 7虚拟机来测试这些内容。
它附带了IE8,但我升级到IE9。
所以我转到了微软的IE9下载页面,然后……
最后关于 HTTP/2 的最后一句话。你知道它现在已经集成到 Node 中了吗? 如果你想玩一下,我编写了一个带有 gzip,brotli 和响应缓存的100行HTTP/2 服务器,带来🚢新的测试乐趣。
关于 bundle splitting 的一切就讲完了。 我觉得这种方法的唯一缺点就是必须不断说服人们相信加载许多小文件是OK的。
Code splitting(别加载你不需要的代码)
这种特别的方法只有在某些站点上才有意义,比如我的。
我想应用我刚想出来的 20/20 规则:如果你的网站的某个部分只有20%的用户访问过,并且这个部分大过你站点 JavaScript 的20%,那么你只需要按需加载代码。
试着调整这些数字,显然,还有比这更复杂的情况。 关键是要有一个阈值,可以确定 code splitting 对于你的网站到底合不合理。
怎么确定?
比如你有一个购物网站,并且想知道是否应该将「支付」代码分开,因为只有30%的用户可以走到支付流程。
你需要做的第一件事是卖质量更好的东西。
第二件事,是计算出这块完全唯一的代码量。 由于你在执行「code splitting」之前应该始终进行「bundle splitting」,所以你可能已经知道这部分代码有多少。
(它可能比你想象的要小,所以在你跃跃欲试之前先把代码量累加一下。比如你有一个 React 站点,那么你的 store,reduce,路由,actions 等都将在整个站点上共享。 完全唯一的部分主要是一些组件和他们的工具。)
然后你注意到,支付页面完全唯一的代码为 7 KB。 该网站的其余部分为 300 KB。 我看到这个会说,emm,我不会费力去拆分这块的代码,有这么几个原因:
-
预先加载它不会减慢速度。 记住你正在并行加载所有这些文件。 可以试试看记录 300 KB 和 307 KB之间的加载时间差异。
-
如果你想之后加载这块的代码,那用户在点击「把我的钱拿走」的时候必须等待这块的文件——这个时候正是你想要它最平滑的时候。
-
Code splitting 要求你改你的项目中的代码。 它引入了异步逻辑,而以前只有同步逻辑。 这不是什么造火箭的学问,但是也具有复杂性,因此我认为应该以可感觉到的用户体验改善为由(去做这件事)。
OK,以上就是所有的类似于「这项令人兴奋的技术可能不适用你」的派对扫兴者的话术了。
我们来看下两个 code-splitting 的例子……
Polyfills
我将从这里开始,因为它适用于大多数网站,并且是一个很好的简单入门。
我在网站上使用了许多花哨的功能,因此我有可以导入我需要的所有polyfills的文件。 它包括以下八行:
require('whatwg-fetch');
require('intl');
require('url-polyfill');
require('core-js/web/dom-collections');
require('core-js/es6/map');
require('core-js/es6/string');
require('core-js/es6/array');
require('core-js/es6/object');
我直接在入口 index.js 的顶部导入此文件。
import './polyfills';
import React from 'react';
import ReactDOM from 'react-dom';
import App from './App/App';
import './index.css';
const render = () => {
ReactDOM.render(<App />, document.getElementById('root'));
}
render(); // 对,目前这一行是无意义的
我们使用 bundle spiltting 部分中的 Webpack config,由于这里有四个 npm 包,我的 polyfill 将被自动拆分为四个不同的文件。 它们总共约 25 KB,并且90%的浏览器不需要它们,所以值得动态加载。
使用 Webpack 4和 import() 语法(不要和没有括号的import语法搞混了),条件加载polyfill是非常容易的。
import React from 'react';
import ReactDOM from 'react-dom';
import App from './App/App';
import './index.css';
const render = () => {
ReactDOM.render(<App />, document.getElementById('root'));
}
if (
'fetch' in window &&
'Intl' in window &&
'URL' in window &&
'Map' in window &&
'forEach' in NodeList.prototype &&
'startsWith' in String.prototype &&
'endsWith' in String.prototype &&
'includes' in String.prototype &&
'includes' in Array.prototype &&
'assign' in Object &&
'entries' in Object &&
'keys' in Object
) {
render();
} else {
import('./polyfills').then(render);
}
有道理吧? 如果所有这些东西都支持的话,就渲染页面。 否则导入polyfills,然后渲染页面。 当此代码在浏览器中运行时,Webpack 运行时将处理这四个 npm 包的加载,并且在下载并解析它们后,调用render() 并继续进行。
(顺便说一句,要使用import(),你将需要Babel的dynamic-import plugin。此外,正如Webpack文档所说,import()用了promises,你需要将这个polyfill与其他polyfill分开去polyfill。)
很简单,是吧?
下面是有些麻烦的例子……
基于路由的动态加载(React 独占)
回到 Alice 的例子,假设该网站现在有一个「管理」部分,商品销售者可以登录并管理他们想要出售的玩意。
这一块具有许多完美的特性,大量的图表以及 npm 中的大型图标库。 我已经做了 bundle splitting,可以看到它们全部超过100 KB。
当前,我有一个路由设置,当用户查看/admin URL时将呈现<AdminPage>。 当Webpack将所有内容打包在一起时,它将找到import AdminPage from './AdminPage.js',然后说“喂,我需要在初始有效载荷中包括它”。
但是我们不希望这样。 我们需要把这个引用放在 admin 页面动态导入里,比如import('./AdminPage.js'),Webpack 就会知道需要动态加载它。
很酷,不需要任何配置。
所以,我不不应该直接引用AdminPage,而是建另一个将在用户访问/admin URL时呈现的组件, 它可能看起来像这样:
import React from 'react';
class AdminPageLoader extends React.PureComponent {
constructor(props) {
super(props);
this.state = {
AdminPage: null,
}
}
componentDidMount() {
import('./AdminPage').then(module => {
this.setState({ AdminPage: module.default });
});
}
render() {
const { AdminPage } = this.state;
return AdminPage
? <AdminPage {...this.props} />
: <div>Loading...</div>;
}
}
export default AdminPageLoader;
这个概念很简单,对吧? 组件mount后(意味着用户位于/admin URL),我们将动态加载./AdminPage.js,然后保存该组件的引用。
在 render 方法中,我们仅仅简单地在等待<AdminPage>加载时渲染<div> Loading ... </ div>,在<AdminPage>加载完成存储它。
我只是出于好玩写了这个例子,实际上你只需要使用react-loadable来实现它,正如 React Code-Splitting 文档说的那样。
好啦,我想这就是全部了。有没有可以总结我上面说过的东西的句子,但用更少的文字?
-
如果人们多次访问你的网站,就把你的的代码分成许多小文件。
-
如果你的网站上有大部分用户不访问的大块内容,动态加载这块代码。
感谢阅读。祝你今天愉快~
靠,我忘了提 CSS 了。
本文由本博客博主 Moltemort 翻译,转载本文请注明源链接